
7. April 2026
Music As Language
On Bad Bunny, a Debate Between Friends, and What We Mean When We Say We Understand
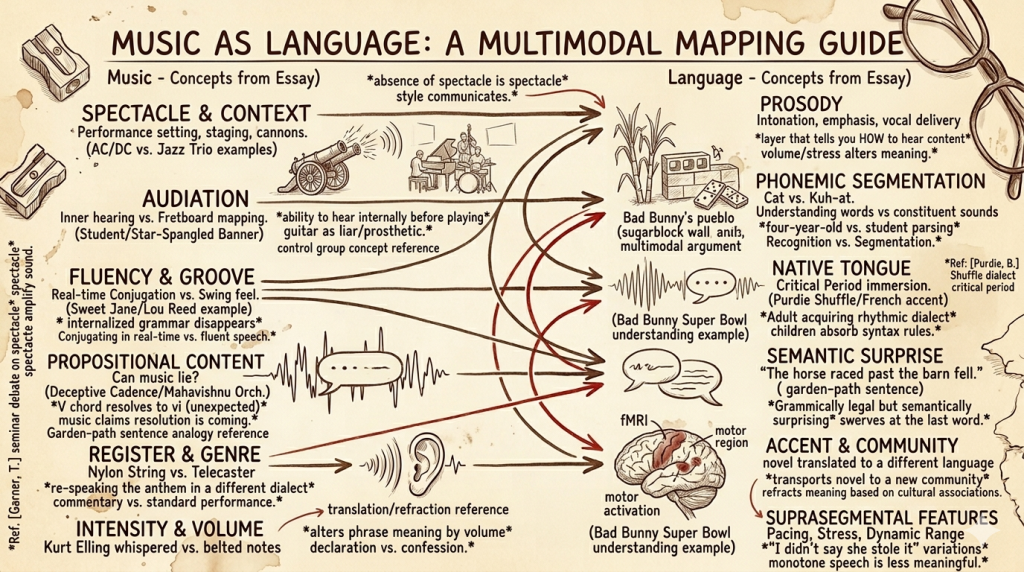
I want to tell you about the night 128 million Americans understood a language they don’t speak—and didn’t even notice they were doing it. On February 8th, 2026, a man walked onto the largest and most obscenely sponsored stage in the history of human-beings-gathered-together-to-watch-a-thing, and performed, for thirteen uninterrupted minutes, an entire concert in a language that the clear majority of his audience did not speak. And they understood it. They understood all of it.
Not the words. Let’s be precise about this, because precision matters when you’re trying to say something that sounds, on its face, like the kind of thing a college sophomore says at 2 a.m. after discovering Noam Chomsky, which is: music is a language. Not a metaphor for a language, not “like” a language in the way that, say, mathematics is “like” a language or fashion is “like” a language or the stock market is “like” a language—which is to say, loosely, approximately, if you squint. Music is a language. Literally. Structurally. Functionally. In ways that are specific and demonstrable and, if I’m being honest, so obvious once you start seeing them that the real mystery is why we keep treating the claim as a metaphor at all.
But: the words. I did not understand the words. I don’t speak Spanish.* And Bad Bunny—Benito Antonio Martínez Ocasio, whose stage name is itself a kind of linguistic act, a recontextualization of childhood vulnerability into adult bravado that tells you more about his whole project than any bio could—was not interested in making this easier for me. He did not, as artists performing for majority-English-speaking audiences on the most commercially pressurized stage in live entertainment are sometimes quietly encouraged to do, throw in a few English verses as a kind of semantic life raft for the monolingual. He sang in Spanish. He rapped in Spanish. He “spoke” to the audience—and I use the quotes advisedly, because what he did was so much more than speaking—in Spanish. The entire Apple Music Super Bowl LX Halftime Show™ was, linguistically, impenetrable to me.
And yet.
I understood the moment he emerged from a corridor of towering sugarcane stalks and the whole stage became a pueblo, a village, dense with life—domino players, piragua vendors, a nail salon, a woman building a cinderblock wall—that what I was watching was not a concert but a homecoming. I understood that the dancers weren’t decoration but argument: that their bodies were making a case for joy as a form of resistance, for pleasure as something you refuse to let anyone take from you. I understood that the sugarcane wasn’t scenery. I understood, without knowing a single lyric, that the final song was a lament about not having held tightly enough to the things that mattered—which turned out to be exactly right, because the song was “DTMF,” and the letters stand for Debí Tirar Más Fotos—“I Should’ve Taken More Photos”—and even this, even the title, I didn’t need translated to feel, because the music had already said it. The melody had bent downward in exactly the way melodies bend when someone is telling you about something they can’t get back.
So the question—and this is the question that is going to organize everything that follows, the question I’ve been circling for twenty-seven or so years of teaching guitar and thinking about what music actually is—is: how? How did I understand a thirteen-minute performance in a language I don’t speak? What was doing the communicating, if not the words? And is the thing that was doing the communicating, whatever we end up calling it, itself a language? Not metaphorically. Actually.
_______________
*Which is itself a small embarrassment I should probably sit with longer than I typically do, given that I live in New Jersey, which is to say: surrounded by Spanish, marinated in it, the phonemes and cadences so ambient in my daily life that I can identify a Dominican accent from a Puerto Rican one at thirty yards but cannot, if pressed, order anything more complicated than a beer. This is relevant because it means I am, with respect to Bad Bunny’s lyrics, in exactly the position of someone hearing pure sound—rhythm, pitch, timbre, dynamics, phrasing—stripped of all semantic content. I am, in other words, the control group.
II.
There was a debate, years ago, in a music therapy class I was taking—one of those seminars where everyone in the room has strong opinions about what music does to people and roughly zero consensus about what music is—that I have never fully stopped thinking about. My best friend, Tom Garner, got into it with another classmate over what we might call the Spectacle Problem. Tom’s position, which he held with the quiet, immovable certainty of someone who has thought about a thing for a very long time and arrived at a conclusion he is not going to be argued out of, was this: we should almost not care what musicians look like. The music itself does the communicating. Everything else—the lights, the costumes, the choreography, the pyrotechnics, the between-song banter, the whole parasitic apparatus of visual entertainment that has attached itself to the act of organized sound—is, at best, irrelevant, and at worst, a distraction so total that it allows actual musical incompetence to hide behind a curtain of spectacle.
Her position, which she held with equal conviction, was the opposite: sometimes the music is, let’s be charitable, not great, and we love the show anyway. Sometimes we are smitten. Sometimes the spectacle is the point, and the music is just the lubricant that keeps the spectacle from squeaking.
And look, I understood both of them, in the way you understand two people describing opposite walls of the same room. Consider the poles of the argument:
On one end: Brad Mehldau. Or Chick Corea. Or any of the jazz pianists who walk onto a stage with roughly the sartorial ambition of someone who dressed up for the occasion of making breakfast, sit down at an instrument, and proceed to do something so harmonically and rhythmically complex that even trained musicians in the audience occasionally lose the thread—and the entire communicative burden falls on the sound. There is nothing else. No lights. No dancers. No production. Just a human being and eighty-eight keys and whatever’s about to happen between them. If the music doesn’t communicate, nothing does, because there’s nothing else there to communicate. The jazz trio is the musical equivalent of a page of prose with no illustrations, no pull quotes, no infographics—just sentences. Just the language itself, naked, doing all the work.
On the other end: AC/DC. Whose music is, and I say this with genuine affection and zero condescension, almost—almost—parodically simple. Three chords. Four, if they’re feeling expansive. The lyrical sophistication of a note passed in eighth-grade study hall. And yet. And yet. The cannons. The actual, literal on-stage cannons that fire during “For Those About to Rock.” Angus Young in the schoolboy outfit, duck-walking across a stage the size of a municipal parking lot. The sheer, magnificent, unapologetic volume of the thing, which is itself a kind of communication, a physical argument made in decibels that your body receives whether your ears consent to it or not. You don’t go to an AC/DC concert to be told something. You go to be hit with something. And anyone who’s been hit with it knows: the hit communicates.
Tom was a jazz guy. Tom was, more specifically, the kind of jazz guy who believed—and this belief was not a pose or an affectation but a genuine, deeply held conviction that organized how he moved through the world—that music, stripped of everything extraneous, was the most honest form of human communication available to us. That a Brad Mehldau solo was a person speaking. That the spectacle wasn’t just unnecessary but actively harmful—a layer of noise laid over the signal, a fog machine of the soul. He didn’t say it with contempt. He said it with something closer to sadness. The way you’d talk about a friend who’d developed a dependency on something that was slowly replacing the real thing with a simulation of the real thing.
Tom died a few years ago.
I mention this not to sentimentalize the argument—though the temptation is real and I am not fully above it—but because the fact that I am still thinking about this debate, still turning it over, still arguing with a man who can no longer argue back, is itself a kind of evidence for the claim I’m trying to make. The argument outlasted one of its participants. That’s what language does. That’s what language is for: to carry meaning past the point where the speaker stops speaking.
And here’s the thing I’ve come to believe, the synthesis I wish I could offer Tom over a beer he’d nurse for two hours while dismantling my position with the patient, affectionate ruthlessness of someone who knows you well enough to be merciless: they were both right. Tom and our classmate. They were both completely right. And the reason their argument felt unresolvable is that they were arguing about whether a sentence matters more than a tone of voice—which is a false choice that actual linguists resolved decades ago by recognizing that communication is, by its nature, multimodal.
The jazz pianist alone on a dark stage isn’t making music without spectacle. The absence of spectacle is the spectacle. The rumpled clothes are the costume. The deliberate refusal to perform is itself a performance—a semiotic choice that says: “I am the kind of musician who lets the music speak.” That message is communicated visually, socially, culturally. It’s the musical equivalent of someone who writes in plain prose and no footnotes**—the simplicity is a style, and styles communicate.
And AC/DC’s cannons aren’t a substitute for musical content. They’re an amplification of it. The music is simple—but simplicity is not the same as emptiness. A I-IV-V chord progression is, harmonically, what “See Spot run” is to English: a sentence so basic that every human being on earth parses it instantly, which means its communicative efficiency is essentially perfect. The cannons don’t replace the musical statement. They’re the prosody—the volume, the emphasis, the physical weight that tells you how to receive the statement. They’re the difference between someone saying “I love you” and someone shouting “I love you” from across a canyon. The words are the same. The meaning is not.
_______________
**Which I appreciate is an almost comically self-defeating footnote to include in an essay that is, at this point, roughly 40% footnotes. But that’s the trap, isn’t it: once you start qualifying your qualifications, the qualifications themselves become the argument. The parenthetical becomes the main clause. The aside becomes the center. And I’d submit that music works exactly this way—that the “ornamental” elements (a grace note, a bend, a slight ritardando before a downbeat) are doing at least as much communicative work as the notes they’re supposedly ornamenting. But we’ll get there.
III.
So: Bad Bunny on the Super Bowl stage™, singing in Spanish to 128 million mostly non-Spanish-speaking viewers, and those viewers understanding him anyway. Tom Garner in a music therapy classroom, insisting that the music itself is the language, the whole language, and nothing but the language, so help him God. His classmate, equally insistent, arguing that the spectacle carries meaning the music alone can’t.
What if they’re all describing the same phenomenon from different angles?
What if music doesn’t just function like a language but is, in every structurally meaningful sense, a language? One with its own phonemes (pitch), its own syntax (rhythm), its own grammar (harmony), its own accents and dialects (timbre), its own prosody (dynamics), its own pragmatics (performance context, visual presentation, the whole apparatus Tom wanted to strip away and his classmate wanted to celebrate)? What if the reason I understood Bad Bunny without understanding Spanish is that Bad Bunny was speaking two languages simultaneously—Spanish, which I don’t speak, and music, which I do—and the musical language was so fluent, so precise, so expressively specific that it carried the full communicative payload on its own?
That’s the claim. And what follows is my attempt to demonstrate it—not through metaphor, but through structure. By showing, element by element, that the parallel between music and language isn’t decorative but architectural. That it holds all the way down. And that the places where it breaks—because it does break, or at least fracture, in ways that are genuinely interesting—tell us something important about both systems that we’d miss if we stopped at the bumper-sticker version of the thesis.
Tom would’ve liked this argument, I think. He would’ve agreed with most of it and fought me on the rest, which is, come to think of it, what a conversation is.
Which is, come to think of it, the point.
IV. Pitch as Phoneme
The smallest unit of a language is the phoneme—a single, irreducible sound that carries no meaning on its own but becomes meaningful in combination. The “buh” sound means nothing. Put it before “ook” and you get “book.” Put it before “at” and you get “bat.” The phoneme is not the message. It is the atom from which messages are built.
Pitch is music’s phoneme. A single note—a C, a B-flat, an F-sharp—played in isolation, means nothing. It has frequency. It has vibration. It has, if you want to get into the physics (and I always want to get into the physics), a fundamental tone and a series of overtones that give it its particular color. But it does not have meaning. It is a sound without a sentence. A syllable in search of a word.
I know this because I watch the failure of pitch-as-meaning every week in my teaching studio. I had a student—a diligent, hardworking guy, the kind of student who practices more than I ask and shows up with his homework done—who was learning “The Star-Spangled Banner.” And he could not, for the life of him, tell me whether the opening phrase (“oh-oh say”) went up or down.
I want you to sit with this for a moment, because it’s stranger than it sounds. The opening of “The Star-Spangled Banner” descends. It doesn’t descend by a subtle half step, either—it drops by a third, then another third. These are relatively largeintervals, or, at least, they’re not stepwise movements. If pitches were stairs, this would be jumping down half a flight in two jumps. And this student, who has heard this melody probably three thousand times in his life—at baseball games, before hockey matches, on television every Fourth of July, accompanied by the Blue Angels screaming overhead—had never once registered that it goes down. Because for him, the melody wasn’t a sequence of pitches. It was a shape. A gestalt. A thing that goes with flyovers and flags and standing with your hand over your heart. The phonemes were there. He could hear “the word.” But he could not hear the individual sounds that composed it.
This is, in linguistic terms, the difference between recognizing a word and being able to segment it into its constituent phonemes. A four-year-old can understand the word “cat” without being able to tell you that it starts with a “kuh” sound. My student could recognize “The Star-Spangled Banner” without being able to tell me which direction its sounds moved. He could identify the sentence but not parse it.
And here’s where the guitar earns its reputation as a liar—because the guitar would have let him play “The Star-Spangled Banner” without ever resolving this problem. The frets would have done the hearing for him. He could have looked at a tab, placed his fingers where the numbers told him to, and produced a phonetically perfect rendition of a melody he could not internally hear. The fretboard is a prosthetic for audiation—for the ability to hear music inside your head before you play it—and like all prosthetics, it does its job so well that you can forget the limb was ever supposed to work on its own.
But here is the other side of pitch-as-phoneme—the side where phonemes, in the hands of a fluent speaker, can carry staggering weight.
There’s an old-ish track by DJ Krush called “Edge of Blue” where trumpet player Nobutaka Kuwabara comes in hot—brazen, screaming—with a single A natural against a rolling B-flat blues-scale bass line—it’s truly badass. If you know anything about tonal harmony, you know this is, on paper, a catastrophic choice. The A natural against B-flat is a half step—the most dissonant interval in the Western system, the sound of two notes so close together they’re essentially trying to occupy the same space and failing. And a major 7 over a clearly dominant chord—a bluesy dominant, no less—it should sound wrong. It should sound like a mistake, like someone stumbled into the wrong key and doesn’t know how to get out.
But Kuwabara doesn’t resolve up to the B-flat, which is what any theory textbook would prescribe. He resolves down—down to the E, the “blue note,” and then up to F, the fifth of the scale, which is where the line really wanted to go all along. And that downward, delayed resolution changes everything. It says: home is not where you think it is. The “correct” resolution would have been a sentence completed as expected. The actual resolution is a sentence that swerves at the last word and lands somewhere more honest. It’s the phonemic equivalent of a poet using a word that technically doesn’t belong—a word that violates the expected pattern—and having that violation carry more meaning than any “correct” word could have. Because the wrongness itself is the message.
One student can’t hear whether a melody goes up or down. One trumpet player uses a single “wrong” note to redefine the entire tonal gravity of a song. The difference between them is the difference between someone who recognizes words and someone who is literate. Phonemes—pitches—mean nothing in isolation. But in the hands of someone who understands how they combine, they are the atoms from which meaning is made.
V. Rhythm as Syntax
Syntax is not word order. This is a common misunderstanding, and it matters. Syntax is the hierarchical system that determines which combinations of words parse as meaningful and which don’t—and, critically, how meaningful elements group together. “The dog bit the man” and “the man bit the dog” use the same words in different syntactic arrangements and produce opposite meanings. “Dog man the the bit” uses the same words in an arrangement that produces no meaning at all. Syntax is what separates language from a bag of words shaken onto a table.
Rhythm is music’s syntax. And I don’t mean this loosely.
I have a student who is learning the rhythm guitar part to “Sweet Jane” by the Velvet Underground. He can explain it to me. He can narrate every element: “downstroke D chord, upstroke silent, downstroke mute, upstroke D, downstroke mute, upstroke A, downstroke mute, upstroke G.” He can describe the syntax of this sentence with perfect accuracy. He can diagram it. He can define every term. What he cannot do is speak it.
When he tries to string these elements together in real time, the result has all the nonchalance of an ambulance on its way to a nine-car pileup. It’s a dog devouring in one bite the crème brûlée you so patiently, delicately cooked so as not to burn it and curdle the pudding. Every individual element is correct. Every “word” is a real word. But the syntax—the flow, the hierarchy of emphasis, the way strong beats and weak beats create a groove that tells the listener how to parse the musical information—is wrong. And the wrongness makes the whole thing unintelligible in exactly the way a syntactically scrambled sentence is unintelligible. He is saying dog man the the bit.
The original “Sweet Jane,” played by Lou Reed, has a lilting, almost lazy swing to it—a rhythmic nonchalance that communicates ease, insouciance, the sense that these chords have been strummed ten thousand times and the hand no longer thinks about strumming them. That nonchalance is a syntactic quality.It cannot be faked. It is the rhythmic equivalent of fluency—the sound of someone who has internalized the grammar so completely that the effort disappears, the way a native speaker doesn’t think about subject-verb agreement. My student is conjugating in real time. Lou Reed conjugated so long ago he forgot there were rules.
And then there’s the deeper syntactic problem—the dialect problem. I played bass for a while in a Steely Dan cover band*, and when we attempted “Home at Last,” the drummer and I just could not get the Purdie Shuffle right. The Purdie Shuffle is a specific rhythmic feel created by the great Bernard Purdie—a half-swung, ghost-note-heavy groove that sits in a rhythmic no man’s land between straight and swung time. Chuck Rainey, the bassist on the original, locks into this groove with a feel so precise and so relaxed that it sounds like the most natural thing in the world. (This is another example of musical badass-ery. I might have to write an essay on this subject.)
We could approximate it. We could get, let’s say, 70% of the way there. But the last 30% was the difference between someone who “speaks a little French” and someone who thinks in French. Purdie and Rainey grew up inside a rhythmic tradition where this groove was mother-tongue fluency. They didn’t learn it; they absorbed it, the way children absorb syntax—not through rules but through immersion. My drummer and I were trying to acquire a rhythmic dialect as adults, past the critical period, and every native speaker in the room could hear the accent.
_______________
*Don’t judge.
Syncopation, meanwhile, is syntax’s most powerful tool—because syncopation is a deliberate syntactic violation. It places emphasis on a beat where the grammar says no emphasis should go, the way a sentence fragment creates emphasis by violating the rules of complete sentences. “I came. I saw. I conquered.” Technically, those are fragments. Syntactically, they’re violations. Communicatively, they’re devastating. Syncopation does the same thing: it “breaks” the expected rhythmic grammar in a way that creates meaning the “correct” version couldn’t. A syncopated groove doesn’t feel wrong. It feels more right—because the violation is itself the message.
VI. Harmony as Grammar
Play a B and the C just above it, together, and ask anyone—musician, non-musician, child, adult, dog for all I care—what they hear, and the answer will be some variation of that sounds awful. It is a half step. It is the most dissonant interval available in the Western tonal system. It can wake you from a deep sleep. It is two phonemes colliding without syntax.
Now: put a C way down low. Add an E and a G just above it. Then put that same B and C on top. What you have is a Cmaj7—one of the most beautiful, pastel, open-curtains-on-a-spring-morning chords in all of Western harmony. The B and C are still there. The dissonance is still there, technically, acoustically. But the meaning has completely changed, because the grammar has changed. The other notes—the C root, the E, the G—provide a syntactic context that transforms the “awful” interval into something luminous.
This is what grammar does. Grammar does not change the words. Grammar changes what the words mean.“Dog bites man” and “man bites dog” contain identical words. The grammar reverses the meaning entirely. A B against a C is anguish. A B against a C inside a Cmaj7 is tenderness. Same notes. Different grammar. Different meaning.
Harmonic grammar, like linguistic grammar, has rules—and the most interesting moments in music are the moments when those rules are violated with intent. Consider the deceptive cadence: a V chord resolving to vi instead of I. In harmonic grammar, V-I is a completed sentence. It is the musical period at the end of a complete thought. Your ear expects it the way your brain expects a subject to be followed by a verb. The deceptive cadence gives you V and then, instead of the expected I, delivers vi—a chord that is grammatically legal but semantically surprising. It is a garden-path sentence. It is the musical equivalent of “the horse raced past the barn fell.”
And here’s where it gets genuinely philosophical: is a deceptive cadence making a claim? Because if it is—if the music is setting up an expectation and then asserting “no, not there”—then music has propositional content. It can say something that is, in some meaningful sense, true or false. More on this later.
The Mahavishnu Orchestra has a track called, appropriately, “Resolution” that simply never resolves. Two minutes of harmonic setup—ascending, climbing, building—and then it ends. No arrival. No I chord. No period. You leave the song the way you’d leave a sentence that
Exactly. The title names the thing the music withholds. That is a propositional act. The music claims resolution is coming. The claim turns out to be false. Music just lied to you. And a thing that can lie to you is a thing with propositional content, which is supposed to be the one thing that separates language from everything else.
At the other end of the spectrum: Kings of Leon, “Use Somebody.” A song whose chord progression is almost comically simple, sitting in a major key so bright and earnest it practically wears its varsity jacket to school. And just at the last possible moment before you’d hit “skip” because it’s too major, too hokey, too saccharine to survive, the bassist plays an A, betraying the key, sliding the ground out from under you and into a minor chord. One note. The grammatical equivalent of a question mark appearing at the end of what you thought was a declarative sentence. “I am happy.” vs. “I am happy?” The bass player didn’t change the words. He changed the punctuation. And the punctuation saved the song from itself.
And then there are my students, who bring in original compositions written on the fretboard rather than the guitar. They choose chords and bass notes based on what looks good visually—what makes a pleasing geometric pattern on the neck. But sounds don’t adhere to visual rules. The result is almost always harmonic gibberish—chords that are individually real chords arranged in a sequence that no ear trained in any tonal tradition would produce. It is the musical equivalent of me throwing together sounds I think “sound Spanish” but that are, to any actual Spanish speaker, pure nonsense. The phonemes are real. The grammar is invented. The meaning is zero.
VII. Timbre as Dialect
Timbre is the quality of a sound that lets you distinguish a trumpet from a violin even when both are playing the same note at the same volume. It is, in linguistic terms, accent. And accent is not decoration. Accent is information.
But timbre goes further than accent. Timbre is register—the full package of social, cultural, and contextual meaning that a particular sound-quality carries. The same melody played on a nylon-string classical guitar and a beat-up Telecaster through a cranked Fender Deluxe isn’t just “different.” It is operating in a different social world. The nylon-string says: recital, conservatory, Segovia, quiet rooms with good acoustics and attentive audiences. The Telecaster says: bar, highway, honky-tonk, a room where people drink and dance and don’t necessarily face the stage. Same phonemes. Same syntax. Same grammar. Different dialect. And the dialect tells you, before a single melodic or harmonic choice has been made, who is speaking and what community they belong to.
The single most famous example of timbre-as-argument in recorded music is one that has been discussed to death but never, I think, fully explained: Jimi Hendrix playing “The Star-Spangled Banner” at Woodstock in 1969. Everyone knows what he did. Everyone says “he made the guitar sound like bombs” and leaves it there, as though the observation is self-evident. But the mechanism is worth unpacking, because it is a precise demonstration of what dialect can do.
Hendrix took the most formally “correct” melody in American public life—a melody that exists, in its standard context, in the timbral register of military brass bands and trained sopranos, performed with the stiff reverence of a salute—and re-spoke it in a completely different dialect. Same phonemes. Same syntax. Same grammar. Completely different accent. And the accent said things the original melody was structurally incapable of saying. The feedback wasn’t noise. It was commentary. The bent notes weren’t mistakes. They were editorial. He wasn’t playing the anthem wrong. He was translating it into a dialect that could express what the original register couldn’t.
And notice how this connects back to my student’s Star-Spangled Banner—the one who couldn’t hear whether “oh say” went up or down, because for him the melody existed in the register of Blue Angels and baseball games. Hendrix heard the same melody and asked: what happens if this sentence, spoken in a different accent, means something the speaker never intended?
The Charlie Hunter Quartet did something even more radical: they recorded the entire Bob Marley album Natty Dread—every track, start to finish—and transformed reggae into horn-drenched funk. Same melodies. Same chord progressions. Completely different timbral world. And the result wasn’t a “cover” in the way that word is usually used, which implies a reproduction with minor variations. It was a translation. The reggae originals spoke to one community, carried one set of cultural associations, lived in one social context. The funk versions spoke to a different community, carried different associations, lived in a different context. The “text” was identical. The “meaning” shifted—not because the notes changed, but because the dialect did. It is what happens when a novel is translated and the translator’s language brings out resonances the original author didn’t consciously put there. The meaning isn’t distorted. It’s refracted.
VIII. Dynamics as Prosody
Here is a sentence: “I didn’t say she stole it.”
This sentence has seven words and, depending on which word you emphasize, seven completely different meanings. “I”didn’t say she stole it (someone else did). I “didn’t” say she stole it (flat denial). I didn’t “say” she stole it (I implied it). I didn’t say “she” stole it (someone else did). And so on. The words are identical in every version. The meaning changes entirely based on emphasis—on prosody, which is the linguistic term for the suprasegmental features of speech: volume, pitch contour, pacing, stress. Prosody is not content. Prosody is the layer that tells you how to hear the content.
Dynamics is music’s prosody. And this is, I think, where Tom Garner’s argument contained its deepest blind spot—because prosody is part of language, not an addition to it. When Tom insisted that the music itself does the communicating and everything else is distraction, he was drawing a boundary around “the music itself” that excluded dynamics, phrasing, the physical intensity of performance—all of which are as integral to musical meaning as vocal emphasis is to spoken meaning. Stripping prosody from language doesn’t reveal the “pure” meaning underneath. It destroys meaning. A sentence spoken in a perfect monotone is not a purer sentence. It is a less meaningful one.
Listen to Kurt Elling—on almost anything, but especially his version of Coltrane’s “Resolution” (yes, that “Resolution” again; the song is stalking this essay), where he puts lyrics to Coltrane’s improvised introduction. Elling’s voice is an instrument of dynamic range so precise that he can shift the meaning of a phrase by altering nothing but its volume. (More badassness, this time from Mr. Elling.) A word whispered and the same word belted are, phonemically and syntactically, identical. Prosodically, they are different statements. One is a confession. The other is a declaration. The content is the same. The meaning is not.
And then there is Meredith Monk, whose work—especially Dolmen Music—takes this to its logical extreme. Monk uses the human voice as a purely musical instrument: no words, no lyrics, no semantic content of any kind. What remains is prosody itself—the rises and falls, the swells and retreats, the dynamic contour of human vocal expression stripped of everything except the thing that tells you how to feel. And it communicates. It communicates powerfully, sometimes overwhelmingly. Which means that prosody alone—dynamics alone—is sufficient for meaning. You don’t need the words. You need the shape of the words. The volume. The breath. The emphasis.
This, incidentally, is exactly what happened when I watched Bad Bunny. I didn’t understand his Spanish. But I heard his prosody—the dynamic contour of his vocal delivery, the places where he leaned in and the places where he pulled back, the shouts and the murmurs—and extracted emotional meaning from it. I was hearing music’s prosody do what linguistic prosody does in every conversation you’ve ever had: tell you not what is being said, but how it is meant.
IX. Form as Narrative Structure
Languages have genres. There is the novel and the short story, the essay and the poem, the tweet and the doctoral thesis. These are not just different lengths. They are different structures—different architectures that organize information in different ways for different purposes and carry different expectations about how meaning will be delivered. You pick up a novel and you expect character development, narrative arc, resolution. You pick up a poem and you expect compression, musicality, the weight of each word amplified by the smallness of the container.
Music has genres too, obviously—but more important than genre is form: the structural architecture of a piece. Verse-chorus-bridge is a storytelling architecture. Sonata form is an argument structure: exposition (here is my thesis), development (here is my thesis interrogated, complicated, turned upside down), recapitulation (here is my thesis, survived). The 12-bar blues is—and I mean this precisely, not whimsically—a joke structure: setup, setup, punchline.
George Thorogood’s “One Bourbon, One Scotch, One Beer” makes this almost absurdly literal. The song opens with a long spoken-word narrative—a rambling story about getting kicked out of his apartment, delivered over a vamp that is emphatically not the 12-bar blues, not yet, because the story isn’t done and the form knows it. The vamp is a holding pattern. It is the narrative structure saying: wait for it. The story builds, the complaints mount, the landlord gets more aggressive—and then, and only then, when the narrative arrives at the bar and the first drink is ordered, the 12-bar blues blooms into full flower. The form doesn’t just accompany the story. The form is the story. Everything before the blues was prologue. The blues is the thesis. The structure itself makes the argument that the whole song exists to make: this man needs a drink. Three of them, actually.
Form is the largest-scale parallel between music and language, and in some ways the most intuitive. We already talk about musical “narratives,” about “tension and resolution,” about “the arc” of a piece. But we tend to treat this language as metaphorical—as a loose analogy between two fundamentally different systems. It is not a loose analogy. It is a structural homology. Music organizes meaning in time using formal structures in exactly the way language organizes meaning in time using narrative structures. The parallel is not decorative. It is architectural.
X. The Fracture Point; or, What Music Can Say That Language Can’t
There is a standard objection to the music-is-a-language claim, and it is serious, and I owe it a serious response: language has propositional content. It can assert things that are true or false. “The cat is on the mat” is either true or it isn’t. Language can refer—it can point to specific objects, events, relationships in the world and say true or false things about them. Music, the objection goes, cannot. Music can make you feel sad, but it cannot tell you why you are sad. It can create tension, but it cannot tell you what the tension is about.
This objection is half right. And the half that’s right is important. Music cannot say “the cat is on the mat.” It cannot refer, in the way language refers, to specific external objects. It cannot make truth claims about empirical states of affairs. If you need to know where the cat is, music will not help you.
But.
We have already seen that a deceptive cadence sets up an expectation and violates it—which is, structurally, an assertion. The music claims resolution is coming and then withholds it. “Resolution” by the Mahavishnu Orchestra claims arrival and delivers absence. The Kings of Leon bassist claims major and delivers minor. These are propositional acts. They are music saying “this is true” and then saying “no it isn’t.” They do not refer to cats or mats. But they refer to expectations—to the listener’s internalized model of how tonal harmony works—and they make claims about those expectations that are structurally indistinguishable from truth claims.
And here is where it gets genuinely interesting: music can say things that language cannot. Language is, for all its power, sequential. One word follows another. One clause follows another. You can layer meaning through syntax and metaphor and allusion, but the basic delivery mechanism is linear. Music can be simultaneous. Harmony is, by definition, multiple pitches occurring at once—multiple “statements” happening in the same moment, each modifying the meaning of every other. There is no linguistic equivalent to a chord. There is no way, in language, to say six things at once and have all six things be modified by their co-occurrence. Language gives you sentences. Music gives you chords.
Music can also express things about time—about the felt experience of duration, of anticipation, of arrival and departure—that language can only describe but never enact. When a piece of music accelerates, you don’t just know it’s speeding up. You feel it speeding up. The medium enacts the meaning. Language can say “things got faster.” Music can make things get faster. The proposition and the experience are the same event.
So the fracture point, on closer inspection, is not a weakness in the music-is-a-language claim. It is a feature. Music and language are not identical systems. They are complementary ones—two languages, each capable of things the other isn’t, overlapping in the vast middle ground of human communication and diverging at the extremes. Language can tell you where the cat is. Music can make you feel what it’s like to look for the cat and not find it. Language describes grief. Music is grief—not a representation of it but a direct, unmediated experience of its temporal shape.
Which brings us, finally, back to Bad Bunny.
* * *
What happened on that stage in Santa Clara was not a concert that happened to be in Spanish. It was a bilingual event—a performance conducted in two languages simultaneously, one of which 128 million viewers understood fluently without ever having been taught it. The Spanish carried the propositional content: the specific narratives, the references to Puerto Rican history and geography, the lyrical wordplay. The music carried everything else: the emotional arc, the cultural context, the prosodic contour, the dynamic shape of longing and joy and defiance and grief. And “everything else,” it turns out, is most of what communication actually is.
Tom was right that the music communicates. Our classmate (her name has been lost to time—if you were in a Berklee music therapy course a hundred years ago and recall arguing about this, hit me up) was right that the spectacle communicates. They were both describing real features of a system that is richer and more structurally complex than either of them, in the heat of that classroom debate, had time to articulate.
And the reason I’m still thinking about it—still turning it over, still arguing with a man who cannot argue back—is not because the argument was unresolvable. It’s because the argument was generative. It produced meaning that outlasted both the moment and one of its participants. It is still speaking.
Which is, if you think about it, what the best music does. It keeps speaking after the last note has stopped. It carries meaning across time, across language barriers, across the gap between the living and the dead. It says things that cannot be said any other way, to people who were never taught to listen, who understand it anyway, who have always understood it, who sit in their living rooms on a Sunday evening watching a man sing in a language they don’t speak and feel, unmistakably, that they have been told something true.
Mary Oliver once wrote that attention is the beginning of devotion. I think she was talking about language. I think she was talking about music. I think she would have said there’s no difference.
Tom would have agreed. He would have said it more quietly. And the quiet would have been the point.
